写在最前面的话
朝着抵抗力最大的路径走
我也不是RL的专家,但我认为GAN是使用RL来解决生成建模问题的一种方式。GAN的不同之处在于,奖励函数对行为是完全已知和可微分的,奖励是非固定的,以及奖励是agent的策略的一个函数。但我认为GAN基本上可以说就是RL。
Ian Goodfellow(生成对抗网络之父)
基于上述原则,成绩不重要,我们进行了以下工作。
一、强化学习
在这里,我们把扰动图生成变成像素点级的一个游戏。
即现在有一个500*500围棋棋盘,请随机在格子中下棋子,系统将返回奖励或惩罚。
据此,引入强化学习的策略梯度算法(Policy Gradient)。
简单来说,神经网络的输入是原始的状态信息,优化即在该状态下执行动作的回报,即Q函数,输出是该状态下执行动作的概率。训练完成之后,神经网络逼近的是最优Q函数。
Q(S, a)
# 其中s为状态,a为动作

以下示例:
(1) 定义参数
N = 500
T = N ** 2
base = np.array([0 for _ in range(T)])
ACTION_DIM = T, T
(2) 定义模型
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(8, (3, 3), activation='relu', input_shape=(N, N, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(16, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(16, (3, 3), activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(ACTION_DIM, activation="softmax"),
])
model.compile(loss='categorical_crossentropy', optimizer=tf.keras.optimizers.Adam(0.01))
print(model.summary())

(3) 动作选择
def choose_action(s):
prob = model.predict(np.array([s.reshape((N, N, 1))]))[0]
return np.random.choice(len(prob), p=prob)
根据模型返回概率生成动作。
(4) 模型迭代
def train(records):
s_batch = np.array([record[0] for record in records])
a_batch = np.array([[1 if record[1] == i else 0 for i in range(ACTION_DIM)] for record in records])
prob_batch = model.predict(s_batch) * a_batch
r_batch = np.array([record[2]*10000 for record in records])
model.fit(s_batch, prob_batch, sample_weight=r_batch, verbose=0)
根据每次结果迭代训练模型。
解释一下
model.fit(s_batch, prob_batch, sample_weight=r_batch, verbose=0)
在这里通过sample_weight给loss加一个权重,进而改变损失函数(loss function),促使神经网络朝着累加期望大的方向优化。
(5) 奖励惩罚
最重要也是最困难的一步。需要定义出合适的奖励和惩罚函数,并给出限制条件。
也就是说游戏中,每画好一个点,都应该有奖励分数+10或者惩罚分数-10,并当所下棋子过多结束本轮游戏。
def sfun(arx):
arr = cv.imread(f"{pdata0}/{idata}")
_arr = arr.copy()
for iarx in np.where(arx == 1)[0]:
y_arx = iarx//N
x_arx = iarx%N
_arr[y_arx-M:y_arx+M, x_arx-M:x_arx+M] = datac
cv.imwrite(f"{pdatat}/_{idata}", _arr)
# .....省略
detectionst = do_detect(darknet_model, imgt, 0.5, 0.4, True)
result_t1 = inference_detector(mmdet_model1, f"{pdatat}/_{idata}")
result_t1 = np.concatenate(result_t1)
# .....省略
# 此处选择检测框概率作为奖励或惩罚关键
sdetectionst = [
np.sum([_[4]*100 for _ in detectionst]),
np.sum([result_t1[_, 4]*100 for _ in range(len(result_t1)) if result_t1[_, 4] > show_score_thr]),
]
bb_score = [0 if np.isnan((_s0-_st)/_s0) or np.isinf((_s0-_st)/_s0) else (_s0-_st)/_s0 for _s0, _st in zip(sdetections0, sdetectionst)]
bb_score = np.sum(_bb_score)
rrr = bb_score * connected_domin_score
return total_area_rate > 0.02 or patch_number > 10, rrr
(6) 开始游戏
for i in range(episodes):
s = base
replay_records = []
while True:
a = choose_action(s)
next_s = s.reshape(T).copy()
next_s[a] = 1
done, r = sfun(next_s)
replay_records.append((s.reshape((N, N, 1)), a, r))
s = next_s
# 回合结束
if done:
print('episode:', i, 'training')
train(replay_records)
print('episode:', i, 'trainend')
break
(7) 结果展示

(8) 过程总结
其实可以看到,训练过程还是跟传统梯度下降训练网络概念相对一致,有趣的地方在于游戏化和状态化。
以探索经验来说,强化学习的关键在于奖励,试想怎么走都没有分数的话,模型无论如何学不会最终结果。
启动机制设置,通过保存最优结果在下次重新开始游戏前进行预训练。
(9) TODO
- <input disabled="" type="checkbox"> 游戏动作优化;
- <input disabled="" type="checkbox"> 奖励或惩罚函数修正;
- <input disabled="" type="checkbox"> 神经网络模型结构优化,对回合数据进行batch;
二、黑盒攻击
一般来说,当有方法能促使白盒模型1、白盒模型2得分最大后,黑盒模型得分甚低,攻击随机陷入局部最优。
并随着黑盒模型的破译,白盒模型分数将先下降,再与黑盒模型分数取得总分最大。是谓平衡。
所以我们始终觉得比赛中黑盒攻击虽然不是提分关键,却是比赛关键。
以下思路基于感觉光试是试不出来黑盒模型的,但只要能拟合出来相对同质的就OK。
其实是黑客思维,破译密码一样的概念。但这还比破译密码简单,因为会返回一定的分数,给你评估这次破译是否合理,误差多少。
(1) 通用方法
基于上述概念,我们需要一个通用方法Baseline,且方法得分不需过高,但各模型得分够均匀。
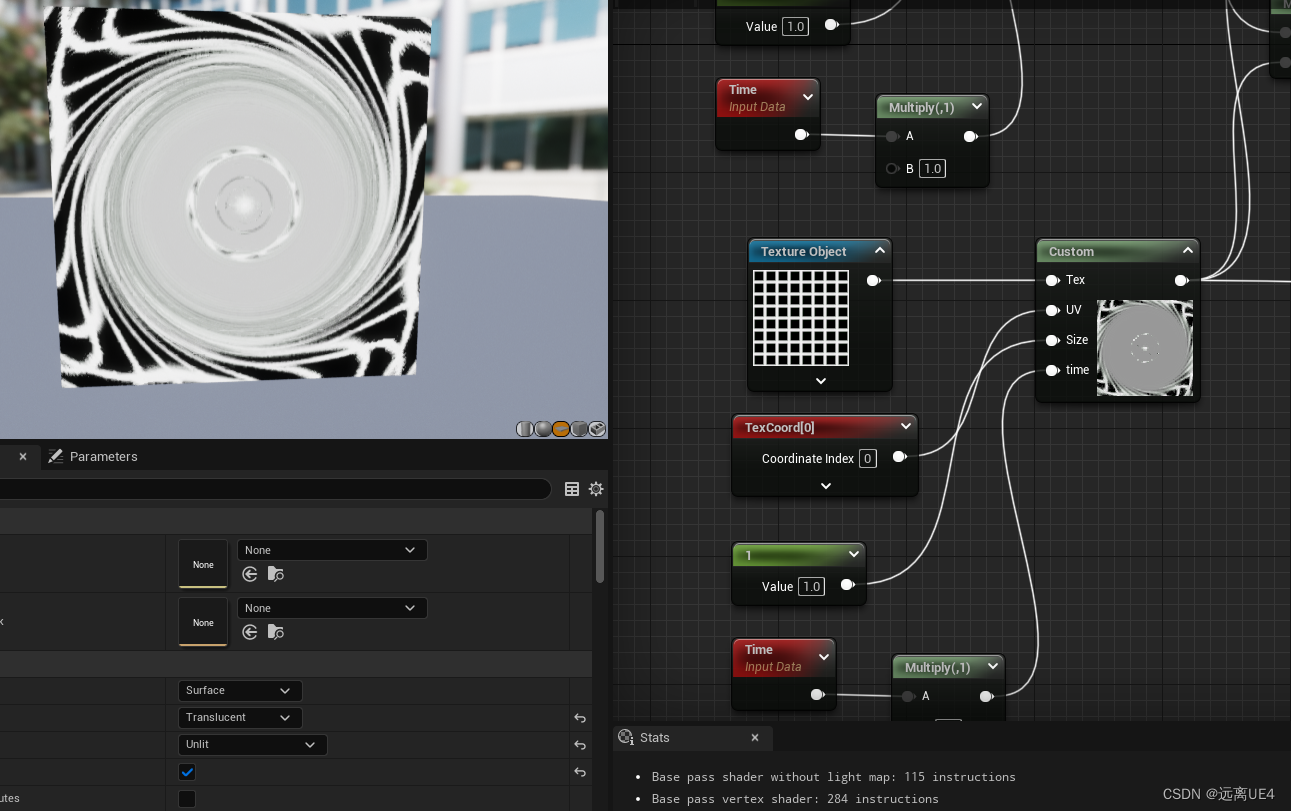
这里我们使用圆靶形贴图。
并通过fpoinnt函数来多次修改圆心。
查看本文全部内容,欢迎访问天池技术圈官方地址:
💪朝着抵抗力最大的路径走-Rank16-强化学习、黑盒攻击、Baseline-SecurityAIRound4_天池技术圈-阿里云天池